Building an image recognition model to classify home types
Kurt McIntire
04.08.2020

Can you guess what type of home this is?
In this blog post, I break down my process for creating a machine learning model that predicts the architectural style of a home, given an image. I'll walk you through the whole process, from brainstorming initial ideas, to building an image dataset, to training a model, to tuning its parameters.
To begin, I brainstormed a few ideas.
- Return beer names, given an image of a beer bottle. Ex. Pliny the Elder given an image of the bottle.
- Return exercise names, given an image of a person exercising. Ex. Squat, given an image of a person performing a squat.
- Return the architecture style of a commercial or government building, given an image. Ex. Art Deco, given an image of a building.
- Return the architecture style of a home, given an image. Ex. Craftsman, given an image of a house exterior.
I chose the fourth idea, to return the architecture style of a home, given an image. I liked this idea because my wife and I are currently "house-crazy". We watch a fair amount of HGTV, house hunting, and home renovation television in the evenings. Over time, I've learned about basic American home types, like Craftsman, Tudor, and Mid-century Modern. However, I still get confused with certain types, like Victorian versus Edwardian.
Here were my steps for building the model.
- Identify types of homes my model should classify.
- Scrape images of these home types.
- Categorize my images by type, in a clean folder structure.
- Delete any scraped images that are classified incorrectly or are low-quality.
- Load my images into a Google Colab notebook.
- Train an
ImageNetextended model using fast.ai. - Verify the accuracy of the model, inspecting common error points.
- Optimize the model.
- Export the model.
Step 1, Select home types for classification
- Cape cod
- Colonial
- Victorian
- Tudor
- Craftsman
- Mediterranean
- Mid-century Modern
- Edwardian
I did not try to classify Ranch and Modern home styles, as I felt that they are too broad of categories. I performed a few image searches for Ranch and Modern home styles. The results were inconsistent and seemed to blend with the other categories. For example, some Ranch style homes had Craftsman and Cape Cod architectural features. And similarly, Modern style homes sometimes returned Mid-Century Modern styles. These were in stark contrast to Tudor, for example, where the images were consistent and distinct.
Step 2, Scrape images
To scrape images, I tried a variety of Google Image Search scraping libraries in the Python language. The most popular one on the fast.ai forums, google-images-download, no longer works. I had to venture out and find a scraping library on my own. After some digging, I found a Bing image search package that worked well. The package requires a Bing Image Search URL as one of its input parameters, and roughly looks like this.
python3 bing_scraper.py --url 'https://www.bing.com/images/search?q=edwardian%20architecture%20home' --limit 30 --download --chromedriver /Users/kurtmcintire/Downloads/chromedriver
For each of my home types, I ran this command, downloading 30 images.
Step 3, Structure folders
Then, I put these images into a folder structure with file naming convention as follows:
data/
cape-cod/cape-cod_1.png...
colonial/colonial.png...
victorian/victorian_1.png...
tudor/tudor_1.png...
craftsman/craftsman_1.png...
mediterranean/mediterranean.png...
mid-century-modern/mid-century-modern_1.png...
edwardian/edwardian_1.png...
Step 4, Clean the data
I then walked thorugh the 30 images, per home type, and took note of the types of images that were downloaded. For the most part, the results of the Bing Image Serach were generally good. However, I noticed some oddities and patterns.
Image oddities and patterns
Delete-worthy qualities
- Images with text over the top or watermarks
- Images that are not the correct architecture type
- Images showing interiors, not exteriors
- Images that include multiple images within
- Images that are very small, less than 224x224 pixels
General oddities that made me pause
- Hand drawn images
- Digital rendering images
- Black and white images
- Some images are .png, and others are .jpg
- In general, most of the images in my dataset are of high-end homes. Will this mean that my model will fail when shown modest homes?
Step 5, Load images into Google Colab
Since I needed strong GPU processing power to train my model, I developed on a Google Colab notebook. I'm still getting used to development inside of notebooks, so it took me about 30 minutes to figure out how to mount the notebook to my personal Google Drive. First, I uploaded all of my images into Google Drive in My Drive/fastai-v3/data/homes. Then, I ran the following code in my notebook.
from google.colab import drive
drive.mount('/content/gdrive', force_remount=True)
root_dir = "/content/gdrive/My Drive/"
base_dir = root_dir + 'fastai-v3/'
path = Path(base_dir + 'data/homes')
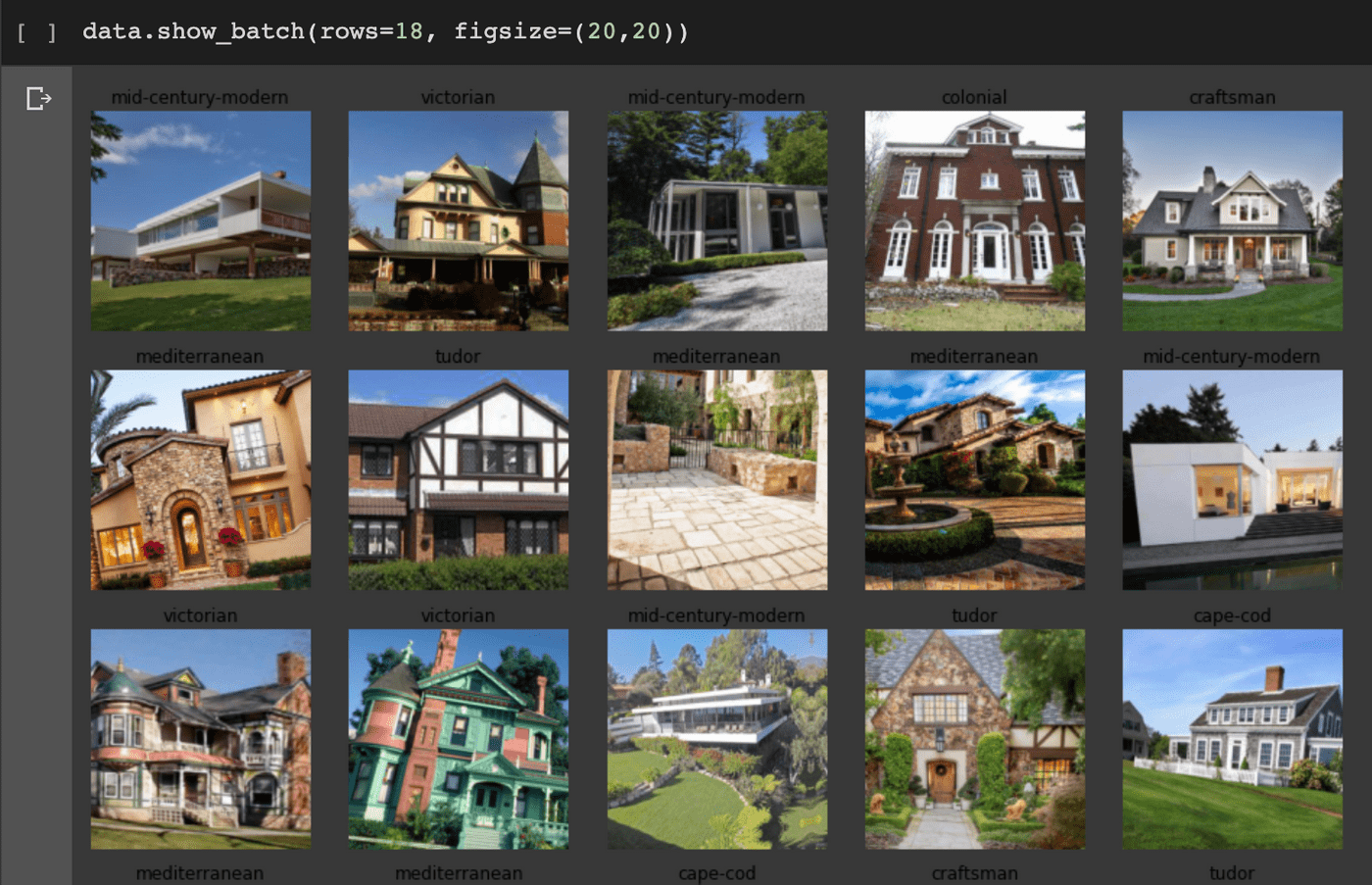
Images loaded with categories
Step 6, Train the model
Following th instructions from lesson 01 of the course, I created an ImageDataBunch from my Google Drive images. 20% of these images are marked as the validation set, and the other 80% are used for training. Also, images were normalized to a size of 224. Then, a convolutional neural network was created, based off of resnet34. Finally, I trained the model using the fit_one_cycle command.
np.random.seed(42)
data = ImageDataBunch.from_folder(path, train=".", valid_pct=0.2, ds_tfms=get_transforms(), size=224, num_workers=4).normalize(imagenet_stats)
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
learn.fit_one_cycle(4)
The fit_one_cycle method returns the error rate for the model over its four iterations.
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 3.482328 | 2.979670 | 0.673913 | 00:04 |
| 1 | 2.961080 | 2.118266 | 0.543478 | 00:04 |
| 2 | 2.432730 | 2.048002 | 0.500000 | 00:03 |
| 3 | 2.048522 | 1.813624 | 0.500000 | 00:04 |
As you can see, my model failed 50% of the time. Not great. Like we did in lesson 01 of the course, I tweaked the learning rate of the model to see if accuracy improved.
learn.fit_one_cycle(2, max_lr=slice(3e-5,3e-4))
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.874060 | 1.616292 | 0.521739 | 00:04 |
| 1 | 0.943877 | 1.484889 | 0.478261 | 00:04 |
After the learning rate tweak, the model improved. However, it still failed 47% of the time. Instead of continuing to tweak the model's parameters, I ran some analysis on the model.
Step 7, Identify common model failures
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()
ClassificationInterpretation.from_learner generated an analysis of the model, and plot_confusion_matrix was used to generate a chart of home types that commonly fail.
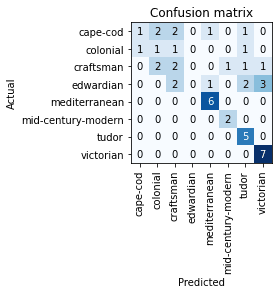
The confusion matrix shows where the model fails. In this case, we want to see the highest numbers on the diagonal, indicating that cape-cod validation images were correctly matched by the model. Numbers not on the diagonal indicate errors.
The most_confused command helped further filter the confusion matrix so I could compare top offending home types.
interp.most_confused(min_val=2)
[('edwardian', 'victorian', 3),
('cape-cod', 'colonial', 2),
('cape-cod', 'craftsman', 2),
('craftsman', 'colonial', 2),
('edwardian', 'craftsman', 2),
('edwardian', 'tudor', 2)]
The output showed that Edwardian and Victorian style homes were most confused by the model. Then, Cape Cod style homes were commonly confused. Again, the higher the value, the more errors occurred. I was not surprised that Edwardian and Victorian styles were confused with one another, as I have a hard time manually distinguishing the two. Visiting several blogs like this, I got the impression that knowing if a house is Edwardian or Victorian is not as easy as identifying a Tudor vs. a Colonial.
I also noticed that the Edwardian style is commonly confused with several other types, not just Victorians. The most_confused function said that Edwardians are also confused with Craftsman and Tudors. Tudors were probably the most distinguished home types, of my set, so I was surprised that the model was incorrectly classifying Edwardians as Tudors.
I then visited the Edwardian image set to see if there were any issues.
Step 8, Optmize the model
Right away, I noticed that I missed a few images that showed interiors of Edwardians, not exteriors. I deleted them. I also saw that my Edwardian images were generally less distinct than the other types of houses. Of my 30 or so Edwardian images, most were difficult to manually categorize. The Edwardian style seems to be a blend of several other styles, similar to the Ranch and Modern styles. I could see how the model was confused.
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 3.404086 | 2.889148 | 0.755556 | 00:50 |
| 1 | 2.890493 | 2.576706 | 0.711111 | 00:51 |
| 2 | 2.237303 | 2.346668 | 0.644444 | 00:52 |
| 3 | 1.868960 | 2.048084 | 0.577778 | 00:51 |
After deleting the interior images of Edwardians, and re-running the model, I saw that the error_rate got worse. My best guess is that by deleting the Edwardian interior images, the model has less distinct information in which to build up its idea of what "Edwardian" is. Now, the model soley has to rely on exterior information. With the bad Edwardian images deleted, I began to explore what we could do with the learning rate.
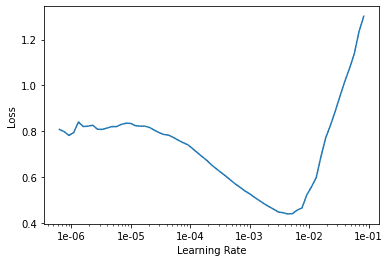
After reading this fast.ai thread about Learning Rates, I identified the minimum loss on the Learning Rate curve. Then, I increased that value by 10x for edge one of my slice. Then, I increased again by 10x to get edge two of my slice. Running these values, I received far better error_rate numbers than I had seen all project.
learn.fit_one_cycle(2, max_lr=slice(1e-4,1e-3))
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.654386 | 1.415758 | 0.355556 | 01:11 |
| 1 | 0.562632 | 1.443581 | 0.333333 | 01:11 |
interp.most_confused(min_val=2)
[('cape-cod', 'tudor', 2),
('colonial', 'cape-cod', 2),
('craftsman', 'tudor', 2),
('edwardian', 'tudor', 2)]
Iterating by increasing image count & rethinking categories
I continued iterating on the model by increasing the image count and rethinking the input categories I was using for various house types. First, increased the input image count, per category, from 30 to 100. Then I changed my search parameters used while scraping images from Bing. Colonial style home generally returned better image searches results than my originally used Colonial architecture home. Then, I introduced higher image scrutiny when inspecting the images returned from the scrape. I eliminated all hand drawn and digital renders.
Next, I rethought my home style categories. The Edwardian home style was a continually low scoring home style due to poor input images on Bing. As I inspected the various Edwardian image search results, I noticed that Victorian homes were intermixed with actual Edwardian homes. Without consistent, high quality images for Edwardian homes, I dropped this category entirely.
While I revisited categories, I replaced the Mediterranean with the tighter scoped Spanish. After inspecting the scraped image results for Spanish homes, I was happpy with their consistency.
I also tried to introduce a new cateogry -- Adobe. Unfortunately, the search results for this popular home style were quite poor. After reviewing 100 scraped images from Bing, I had to delete nearly 85. I chose to not introduce this category.
Finally, I retrained the model using resnet50, more images, better categories, and higher image consistency. I saw a nearly 10% improvement model accuracy.
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.610421 | 1.063648 | 0.264957 | 00:10 |
| 1 | 0.473518 | 1.007051 | 0.239316 | 00:10 |
interp.most_confused(min_val=2)
[('cape-cod', 'craftsman', 5),
('colonial', 'craftsman', 3),
('cape-cod', 'colonial', 2),
('cape-cod', 'victorian', 2),
('colonial', 'cape-cod', 2),
('victorian', 'cape-cod', 2),
('victorian', 'colonial', 2)]
Iterating by manipulating image size
Next, I tried to imprvoe the model by increasing the size of my input images. I bumped the input image size from 224x224 pixels to 448x448. On training, I ran out of memory with my Google Colab notebook. I then tried 336x336 and experienced the same result -- out of memory. After trying these larger image sizes, I upgraded my Google Colab account to Colab Pro, which costs $9.99/mo and gives my notebooks double RAM. Interestingly, I continued to run out of memory when using the 448x448 and 336x336 image sizes. I was, however, able to generate a new model using 280x280 image sizes.
Surprisingly, this resulted in a higher error rate model, as shown below:
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.392485 | 1.023360 | 0.282051 | 00:07 |
| 1 | 0.328660 | 0.965396 | 0.273504 | 00:07 |
Step 8, Export the model
With the resnet50 224x224 image size model functionining with a 23% error rate, I wrapped up the homework. Clearly more improvements could be made if this model were to be used in production. However, for the purposes of Lesson 01 of this homework, I felt that I achieved my goal.
fast.ai has simple learn.export() syntax for exporting a model .pkl file format. This file could be hosted on a server and accessed via an API.
Conclusion
I am satisfied that I was able to generate a 23% error rate model relatively quickly. However, if I were to continue improving the accuracy of this model I'd definitely collect more images, especially for the home types that often confused. If I were to ship this model in production, I'd like to see an error rate of 10% or less.